
oracle创建索引、索引类型(oracle索引的使用详解)
Oracle索引
Oracle索引(index)最大的作用是用来优化数据库查询的效率,提升数据库的查询性能。就好比书的目录一样,可以通过目录来直接定位所需内容存在的页数,大大提高检索效率。
Oracle数据库中如果某列出现在查询的条件中,而该列的数据是无序的,查询时只能从第一行开始一行一行的匹配。创建索引就是对某些特定列中的数据进行排序或归类,生成独立的索引表。在某列上创建索引后,如果该列出现在查询条件中,Oracle 会自动的引用该索引,先从索引表中查询出符合条件记录的 ROWID,由于 ROWID 是记录的物理地址,因此可以根据 ROWID 快速的定位到具体的记录,当表中的数据非常多时,引用索引带来的查询效率非常可观 。
何时建立索引:
既然我们都知道建立索引有利于查询速率的提升,那是不是所有字段都可以加上索引。这是万万不行的,建立索引不仅仅要浪费空间来存储索引表,当数据量较少时,直接查询数据比经过查询索引表再定位到表数据的速度更快。索引可以提高查询的效率,但是在数据增删改时需要更新索引,因此索引对增删改时会有负面影响。所以要根据实际情况, 考虑好再建立索引。
那何时建立索引,下面大概介绍几点,其余的得在实际应用和开发过程中,酌情考虑:
1、Oracle 数据库会为表的主键和包含唯一约束的列自动创建索引,所以在建立唯一约束时,可以考虑该列是否必要建立。是否经常要作为查询条件。
2、如果某个表的数据量较大(十几二十万以上),某列经常作为where的查询条件,并且检索的出来的行数经常是小于总表的5%,那该列可以考虑建立索引。
3、对于两表连接的字段,应该考虑建立索引。如果经常在某表的一个字段进行Order By 则也经过进行索引。
4、不应该在小表上建立索引。上面也说过,小表之间查询的数据会比建立索引的查询速度更快,但是在某些字段,如性别:只有男、女和未知三种数据时,可以考虑位图索引,可以增加查询效率。
5、经常进行DML操作,即经常进行增删改的操作的表,创建表索引时就要权衡一下,因为建索引会导致进行DML操作时速度变慢。所以可以根据实际情况,选择某些字段建立索引,而不能盲目乱建。
索引的类别:
适当的使用索引可以提高数据检索速度,那Oracle有哪些类型的索引呢?
1、b-tree索引:Oracle数据中最常见的索引,就是b-tree索引,create index创建的normal就是b-tree索引,没有特殊的必须应用在哪些数据上。
2、bitmap位图索引:位图索引经常应用于列数据只有几个枚举值的情况,比如上面说到过的性别字段,或者我们经常开发中应用的代码字段。这个时候使用bitmap位图索引,查询效率将会最快。
3、函数索引:比如经常对某个字段做查询的时候经常是带函数操作的,那么此时建一个函数索引就有价值了。例如:trim(列名)或者substr(列名)等等字符串操作函数,这个时候可以建立函数索引来提升这种查询效率。
4、hash索引:hash索引可能是访问数据库中数据的最快方法,但它也有自身的缺点。创建hash索引必须使用hash集群,相当于定义了一个hash集群键,通过这个集群键来告诉oracle来存储表。因此,需要在创建HASH集群的时候指定这个值。存储数据时,所有相关集群键的行都存储在一个数据块当中,所以只要定位到hash键,就能快速定位查询到数据的物理位置。
5、reverse反向索引:这个索引不经常使用到,但是在特定的情况下,是使用该索引可以达到意想不到的效果。如:某一列的值为{10000,10001,10021,10121,11000,....},假如通过b-tree索引,大部分都密集发布在某一个叶子节点上,但是通过反向处理后的值将变成{00001,10001,12001,12101,00011,...},很明显的发现他们的值变得比较随机,可以比较平均的分部在各个叶子节点上,而不是之前全部集中在某一个叶子节点上,这样子就可大大提高检索的效率。
6、分区索引和分区表的全局索引:这两个索引是应用在分区表上面的,前者的分区索引是对分区表内的单个分区进行数据索引,后者是对分区表的全表进行全局索引。分区表的介绍,可以后期再做单独详解,这里就不累述了。
索引的创建
语法结构:
create[unique]|[bitmap] index index_name --UNIQUE表示唯一索引、BITMAP位图索引 on table_name(column1,column2...|[express])--express表示函数索引 [tablespace tab_name] --tablespace表示索引存储的表空间 [pctfree n1] --索引块的空闲空间n1 [storage --存储块的空间 ( initial 64K --初始64k next 1M minextents 1 maxextents unlimited )];
语法解析:
1、UNIQUE:指定索引列上的值必须是唯一的。称为唯一索引,BITMAP表示位图索引。
2、index_name:指定索引名。
3、tabl_name:指定要为哪个表创建索引。
4、column_name:指定要对哪个列创建索引。我们也可以对多列创建索引,这种索引称为组合索引。也可以是函数表达式,这种就是函数索引。
修改索引:
1、重命名索引:
alter index index_old rename to index_new;--重新命名索引
2、合并索引、重新构造索引:我们索引建好后,经过很长一段时间的使用,索引表中存储的空间会产生一些碎片,导致索引的查询效率会有所下降,这个时候可以合并索引,原理是按照索引规则重新分类存储一下,或者也可以选择删除索引重新构造索引。
alter index index_name coalesce;--合并索引 alter index index_name rebuild;--重新构造
删除索引:
drop index index_name;
查看索引:
select t.INDEX_NAME,--索引名字 t.index_type,--索引类型 t.TABLESPACE_NAME,--表空间 t.status,--状态 t.UNIQUENESS--是否唯一索引 from all_indexes T where t.INDEX_NAME='index_name';
案例分析:
案例1、学生信息表(stuinfo)创建的时候就对学号(stuid)设置了主键(PK_STUINFO),当我们学生信息表数据量大的情况下,我们明显发现班号(classno)需要一个索引,不仅仅是用来关联班级信息表(class)、而且经常作为查询条件,因此创建脚本如下:
create index STUDENT.IDX_STUINFO_CLASSNO on STUDENT.STUINFO (CLASSNO) tablespace USERS pctfree 10 initrans 2 maxtrans 255 storage ( initial 64K next 1M minextents 1 maxextents unlimited );
案例2、对于学生信息我们经常用性别作为统计条件进行对学生信息进行统计,因此我们可以在性别(sex)建立一个位图索引进行查询优化。代码如下:
create bitmap index STUDENT.IDX_STUINFO_SEX on STUDENT.STUINFO (SEX) tablespace USERS pctfree 10 initrans 2 maxtrans 255 storage ( initial 64K next 1M minextents 1 maxextents unlimited );
查询一下三种索引的状态:
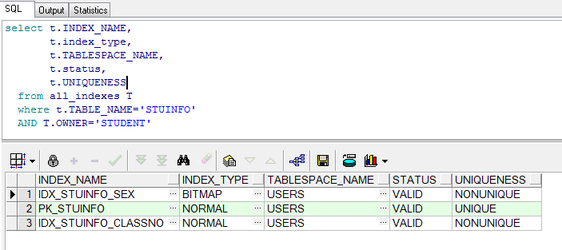
select t.INDEX_NAME, t.index_type, t.TABLESPACE_NAME, t.status, t.UNIQUENESS from all_indexes T where t.TABLE_NAME='STUINFO' AND T.OWNER='STUDENT'
结果如下:
原文地址:https://tangjiusheng.com/it/1201.html
- oracle创建索引、索引类型(oracle索引的使用详解)
- css删除线的属性设置(text-decoration删除线属性介绍)
- Oracle恢复删除的数据(Oracle数据库的备份与恢复)
- 数据库12种数据类型简写(oracle数据库常用数据类型)
- plsql连接oracle配置教程(分享plsql连接oracle数据库详解)
- Oracle是什么软件(Oracle数据库是什么)
- localStorage用法(前端读取localstorage数据的方法)
- oracle和mysql区别(快速了解这9大区别)
- querySelectorAll干嘛用的(querySelector和querySelectorAll的使用方法)
- oracle视图是什么(一分钟了解oracle视图和表的区别)
 赣公网安备36072102000190
赣公网安备36072102000190